| 【论文笔记】Active Learning by Feature Mixing (CVPR2022) | 您所在的位置:网站首页 › 翻译 active › 【论文笔记】Active Learning by Feature Mixing (CVPR2022) |
【论文笔记】Active Learning by Feature Mixing (CVPR2022)
|
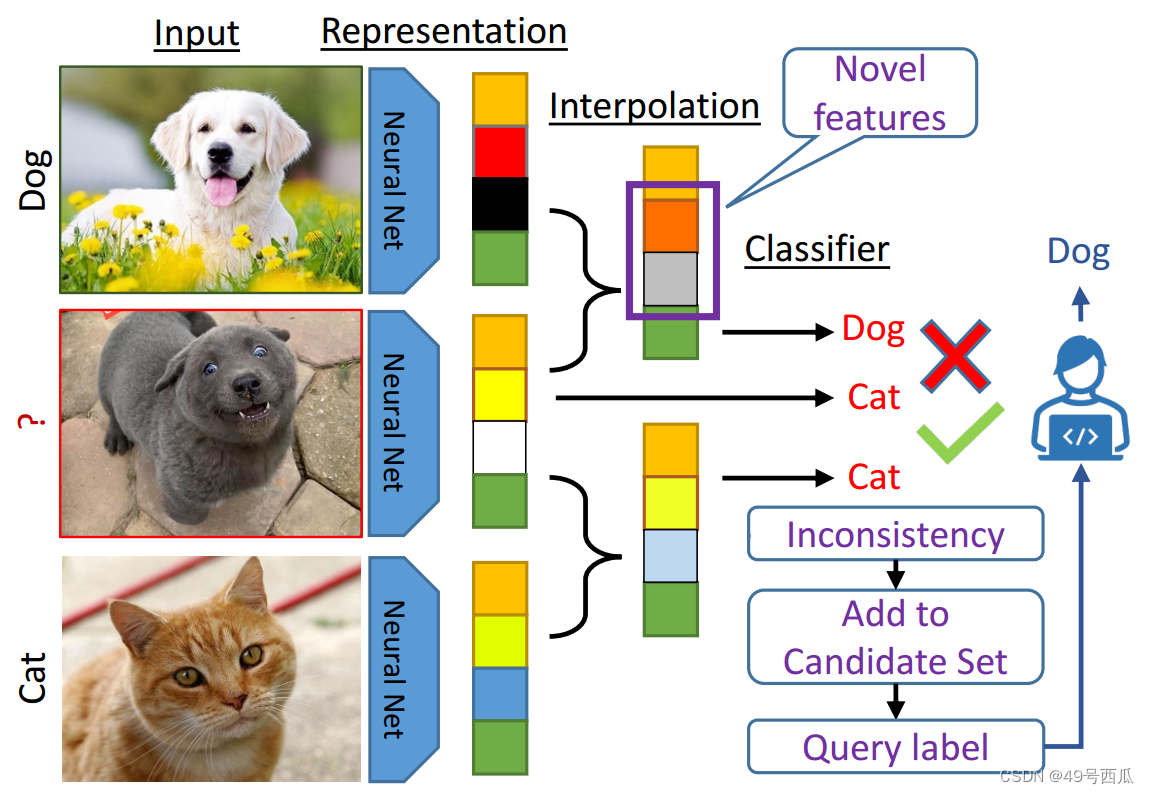
论文:https://arxiv.org/abs/2203.07034 代码:https://github.com/aminparvaneh/alpha_mix_active_learning 1. 介绍本文针对图像分类任务提出了一种简洁有效的主动学习方法,主要通过将无标签数据和有标签数据在隐层空间的表征进行加权插值,为了找到使得扰动后的标注数据预测不一致性最大的插值系数,通过证明提出了插值权重系数的闭合式解。筛选出不一致性程度最大的无标签数据,并进行聚类得到多样性的采样结果,作为查询标注的样本。本文的实验针对MLP、CNN、Transformer模型,在非视觉分类数据、ciifar10/100、Mini-ImageNet、视频分类数据上,总共30种实验设定下,提出的方法均表现出了不错的性能。 本文从学习模型中抽取的分类层之前的输出的D维向量作为表征representation,本文认为将无标注数据的表征与有标注数据的表征进行混合插值,是一种不需要对标注和未标注图像进行显式的建模就可以采样得到新样本的方式。 在样本选择阶段,可以在无标注数据中,找到能使预测分类结果改变的变化的样本,作为候选集。在候选集的样本个数I大于可标注数B时,可以通过kmeans(k为B)采样得到具有多样性的B个样本送给专家标注。 4.1 本文和其他baseline的区别 对比BADGE:本文和BADGE的主要区别在BADGE只依赖于无标注图的梯度,但是正文公式(3)表明本文同时考虑了无标注数据与标注集anchor的差距,以及梯度。 采用特征扰动:对无标注图像采用特征扰动而不是基于anchor的插值,查找不一致性集然后再聚类选择,发现比badge要好,但是仍然差于alphamix,这里只考虑的是特征的新颖性,更说明本文同时考虑了无标注数据新颖性和梯度的优越性。 特征分布对齐:关于隐层特征空间的标注集和无标注集之间的分布的差距,最终将其改写成如下公式: 基于梯度的插值优化 本文参考资料【1】【论文笔记】Multi-Anchor Active Domain Adaptation for Semantic Segmentation(ICCV2021 Oral) 【2】对偶范数的定义和性质 |
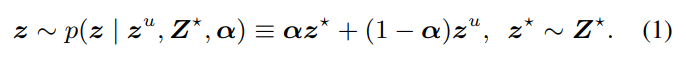 上式中,在具体实现中,
z
u
z^{u}
zu是单个无标注图像,
z
∗
z^{*}
z∗用的是将已标注数据中每个类别的表征均值(本文称为anchor,论文[1]中的anchor的概念类似),
α
\alpha
α是属于0到1之间的D维权重。 混合后的特征与伪标签的损失值,通过一阶泰勒展开可以近似得到:
上式中,在具体实现中,
z
u
z^{u}
zu是单个无标注图像,
z
∗
z^{*}
z∗用的是将已标注数据中每个类别的表征均值(本文称为anchor,论文[1]中的anchor的概念类似),
α
\alpha
α是属于0到1之间的D维权重。 混合后的特征与伪标签的损失值,通过一阶泰勒展开可以近似得到: 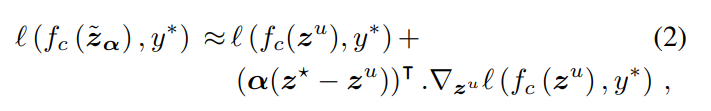 无标注图像混合后的特征和原始表征对应的两个分类损失为:
无标注图像混合后的特征和原始表征对应的两个分类损失为: 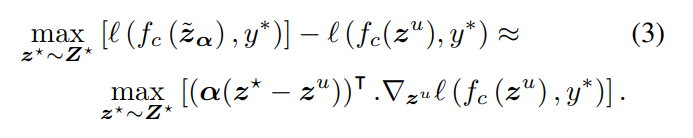 找到使得以上损失差值最大的已标注集的anchor,然后需要求解最佳的特征混合参数
α
\alpha
α。通过对偶范数的性质[2]可以证明其近似最优解为:
找到使得以上损失差值最大的已标注集的anchor,然后需要求解最佳的特征混合参数
α
\alpha
α。通过对偶范数的性质[2]可以证明其近似最优解为: 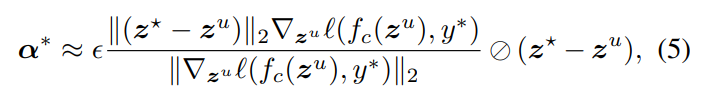
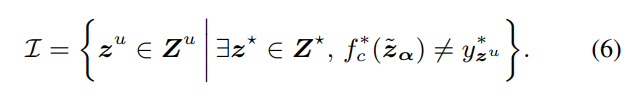
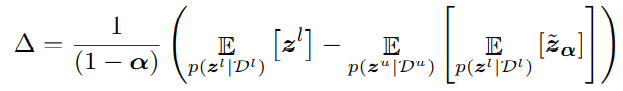 上式中
z
l
z^{l}
zl、
z
l
z^{l}
zl是标注特征和无标注特征,带波浪号上缀的
z
α
z_{\alpha}
zα是插值后的混合特征。这里说明一个插值操作仅仅只以常数相乘,影响了分布期望的差距。通过一个插值的操作代替了分布之间散度度量的操作。具体来讲,公式(1)中,通过对未标注图朝着标注图像插值的方式,在标注和未标注图像之间的分布之间采样,如果采样出来的特征的预测输出与原来的未标注图像不一致,说明这种分布的差距大。
上式中
z
l
z^{l}
zl、
z
l
z^{l}
zl是标注特征和无标注特征,带波浪号上缀的
z
α
z_{\alpha}
zα是插值后的混合特征。这里说明一个插值操作仅仅只以常数相乘,影响了分布期望的差距。通过一个插值的操作代替了分布之间散度度量的操作。具体来讲,公式(1)中,通过对未标注图朝着标注图像插值的方式,在标注和未标注图像之间的分布之间采样,如果采样出来的特征的预测输出与原来的未标注图像不一致,说明这种分布的差距大。【本文地址】